Google and NVIDIA Just Found Two Different Ways to Make AI Way Cheaper
Running AI is expensive. A big reason why? Memory.
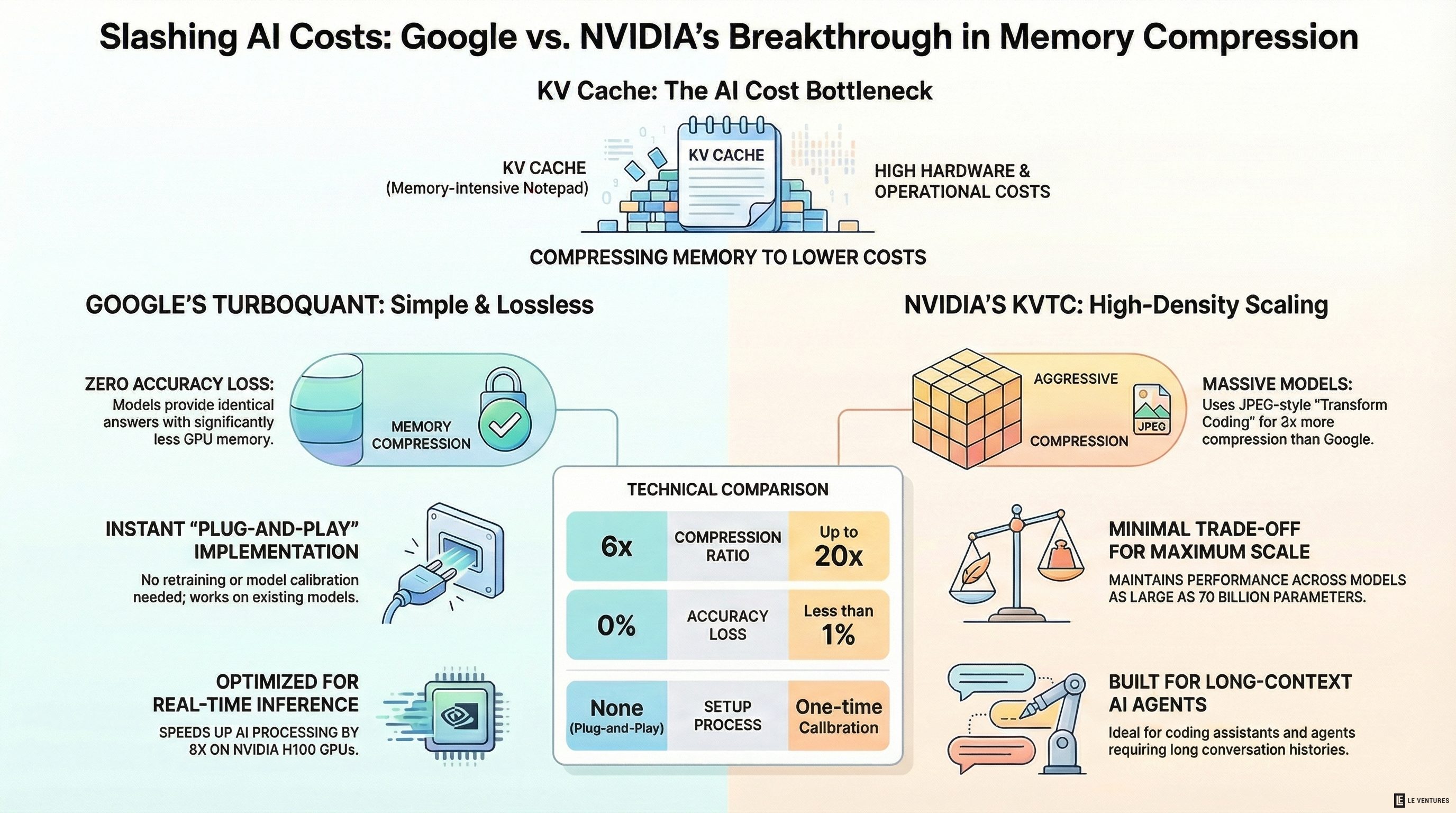
Every time a chatbot answers a question or writes code, it stores a running log of the conversation in something called a KV cache. Think of it like a notepad the AI keeps while it talks to you. The longer the conversation, the bigger the notepad gets - and the more expensive GPU memory it takes up.
Two of the biggest companies in tech just dropped competing solutions to this problem. Both will be presented at ICLR 2026 in April. And both could change how much it costs to run AI.
Google’s TurboQuant: Simple and Lossless
Google built TurboQuant to shrink the KV cache by 6x - and speed up a key part of AI processing by up to 8x on NVIDIA H100 GPUs.
The best part? It loses zero accuracy. The AI gives the same answers. It just uses a lot less memory to get there.
Here’s what makes it stand out:
- No training needed. You don’t have to retrain or fine-tune your model. Just plug it in.
- No calibration. It works the same way on every model, with no setup per model.
- Proven math. It uses a technique called PolarQuant to convert data into a simpler format, then a 1-bit error correction step to clean up the tiny mistakes left over.
Google tested it on Gemma, Mistral, and Llama 3.1 models (all in the 7-8 billion parameter range). Across tasks like question answering, code writing, and summarization - no accuracy loss.
The internet is already calling it the real-life version of Pied Piper from HBO’s Silicon Valley. Memory chip stocks from Samsung, Micron, and SK Hynix dropped after the announcement. Investors worry that if AI companies can compress memory use this much with software, they might not need as many chips.
NVIDIA’s KVTC: More Aggressive, More Compression
NVIDIA’s approach is called KVTC - KV Cache Transform Coding. It borrows ideas from how JPEG compresses images and applies them to AI memory.
The result? Up to 20x compression. That’s more than three times what TurboQuant achieves. The tradeoff is a tiny accuracy drop - less than 1 percentage point in most tests.
How it works:
- PCA decorrelation. It reorganizes the data so similar values are grouped together, making it easier to compress.
- Smart bit budgeting. Important data gets more bits. Less important data gets fewer - sometimes zero.
- Entropy coding. It packs everything down tight using the same kind of compression used in ZIP files, running right on the GPU.
- Critical token protection. It knows not to compress the most important parts of the conversation - the very first tokens and the most recent ones.
NVIDIA tested KVTC on a wider range of models, from 1.5 billion to 70 billion parameters. That includes Llama 3, Mistral NeMo, and Qwen 2.5. It consistently beat other compression methods across coding, math, and long-context tasks.
The catch: KVTC requires a one-time setup step for each model. You run a calibration pass once, save the result, and reuse it forever. Not a big deal, but it’s one more step compared to TurboQuant’s plug-and-play approach.
How They Compare
| TurboQuant (Google) | KVTC (NVIDIA) | |
|---|---|---|
| Compression | 6x | Up to 20x |
| Accuracy loss | Zero | Less than 1 point |
| Setup needed | None | One-time calibration |
| Models tested | Up to 8B params | Up to 70B params |
| Best for | Real-time inference | Long conversations, multi-turn agents |
They actually solve slightly different problems. TurboQuant works in real-time as the AI runs. KVTC is better for storing and reusing conversation history across turns - great for coding assistants and AI agents that run in loops.
Why This Matters for Businesses
If you use AI in your business - chatbots, product recommendations, customer support, coding tools - this is about cost.
AI inference (running the model, not training it) is where most of the money goes for companies using AI day to day. These compression methods could cut that cost significantly.
Shorter term: Cloud providers like Google Cloud and AWS will likely bake these into their AI services. You won’t need to do anything - your AI tools just get cheaper to run.
Longer term: Smaller companies could run bigger AI models on less hardware. A model that used to need four GPUs might fit on one. That opens doors for businesses that thought advanced AI was out of their budget.
What Happens Next
Both papers debut at ICLR 2026, April 23-25. Google plans to open-source TurboQuant around Q2 2026. NVIDIA is building KVTC into its Dynamo inference engine with vLLM support.
It’s also possible to use both together. TurboQuant for real-time compression during a conversation, KVTC for storing the cache afterward. The two approaches don’t conflict - they complement each other.
The race to make AI cheaper just got two big entries. And for businesses that rely on AI, cheaper inference means better margins, faster tools, and more room to experiment.
The AI infrastructure landscape is shifting fast. If you’re evaluating AI tools for your business and want to understand how changes like these affect your costs, start with a free audit.